Andrej Karpathy released microgpt on February 12, 2026: a complete GPT implementation in 200 lines of pure Python with no dependencies. The claim that came with it was striking: "Everything else is just efficiency."
That's a strong claim. I think it's mostly right, but I wanted to work through where it holds and where it might crack.

The Core Claim
What microgpt demonstrates is the atomic unit of modern LLMs: next-token prediction via a transformer. You have token embeddings, position embeddings, self-attention, feedforward layers, residual connections, and a softmax over the vocabulary. That's the algorithm. Scale it up, optimize the hell out of it, and you get GPT-4.
The "everything else" Karpathy refers to includes: BPE tokenizers instead of character-level, trillions of tokens of training data instead of 32k names, bfloat16 precision, distributed training across thousands of GPUs, RLHF for post-training, and on and on. These are engineering challenges, not algorithmic ones.
I find this framing clarifying. But I wanted to test it against two architectural trends that feel like they might be more than efficiency: Mixture of Experts and multimodality.
Mixture of Experts: Same Unit, Different Routing
MoE models like Mixtral, DeepSeek, and OpenAI's gpt-oss series don't change the atomic unit. They replicate it.
Instead of a single feedforward network (MLP) in each transformer block, you have N expert MLPs. A learned router decides which expert(s) to activate for each token. The attention mechanism is unchanged. The residual stream is unchanged. The core loop of "embed, attend, feedforward, predict" is unchanged.
What MoE does is decouple total parameters from active parameters. A 100B parameter MoE model might only activate 10B parameters per token. This is an efficiency technique in the truest sense: you get more capacity without proportionally more compute at inference time.
Karpathy's claim holds here. The algorithm is the same. MoE is a clever way to scale it.
Multimodality
Multimodal LLMs handle images, audio, video, and documents by converting them into the same format the transformer already understands: token embeddings.
Each modality has its own encoder. Vision transformers turn image patches into embeddings. Audio encoders like Whisper turn waveforms into embeddings. These encoders are sometimes pretrained separately (like CLIP) and sometimes trained end-to-end. The encoder outputs then pass through a projector layer, usually a linear layer or small MLP, that matches the embedding dimensions so everything can be concatenated with the text tokens.
Text is the native modality. It just gets tokenized and looked up in an embedding table. No encoder, no projector. The other modalities get projected into text's space.
Once everything is concatenated into a single token sequence, the transformer processes it using the same operations microgpt demonstrates. The model doesn't "know" whether a given embedding came from text or an image. It just processes embeddings.
The encoders and projectors don't change the core algorithm. They change what gets fed into it.
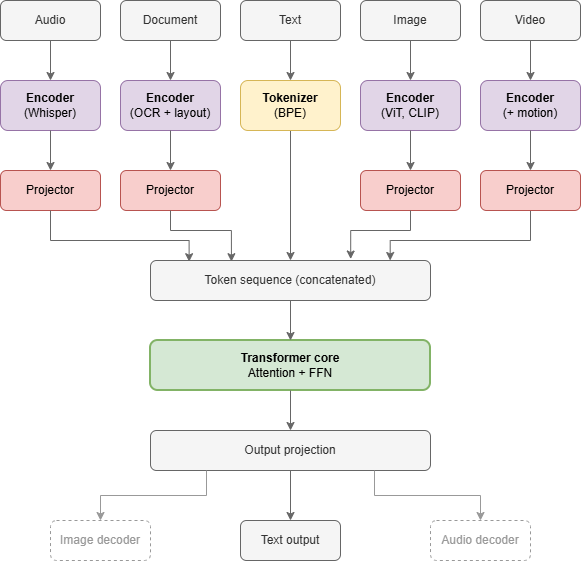
To be more concrete about what these encoders do:
For images, the standard pipeline divides the image into patches (typically 16x16 pixels), runs them through a Vision Transformer like CLIP or SigLIP, and then passes the output through a projector layer. The projector is often just a linear layer or a small two-layer MLP. Its job is to match the embedding dimensions of the text tokens so everything can be concatenated. Sebastian Raschka's walkthrough of multimodal LLM architectures covers this in detail.
For audio, the pattern is similar but the encoders are different. Whisper is the most common choice for speech. Wav2vec and HuBERT are alternatives that learn representations through self-supervised training. Some models use both: a speech encoder plus a separate audio event encoder, because Whisper is optimized for speech recognition and can miss non-speech sounds like background noise or music.
For video, the basic approach is to sample frames and run each through an image encoder. But that misses motion and sequence. State-of-the-art video models add explicit modules between the vision encoder and the LLM to capture what happens across frames. The STORM paper from NVIDIA Research introduces a Mamba-based temporal projector that integrates what they call "temporal dynamics" into visual tokens before passing them to the LLM.
All of these pipelines eventually project into a shared embedding space where the transformer core operates. But there's a simpler alternative that avoids this complexity entirely.
In a text-intermediate pipeline, you convert everything to text before the LLM sees it. Images become captions. Audio becomes transcripts. Videos become frame descriptions plus speech transcription. NVIDIA's documentation on multimodal RAG describes this as grounding information "in one common modality, such as text."
The tradeoff is information loss. A transcript doesn't capture tone of voice. A caption doesn't preserve spatial relationships. The "Localizing Step-by-Step" paper on long video grounding used this approach, transcribing speech and captioning frames to generate text input for localization. It worked, but the authors noted this textual representation only "retains crucial localization information" to a degree.
Modern vision-language models use either "unified embedding" approaches (where vision tokens get projected into the same space as text) or "cross-attention" approaches (where vision features condition the LLM through separate attention layers). Either way, the transformer backbone processes embeddings using the same operations microgpt demonstrates.
Gemini Embedding 2: Native Multimodality
On March 10, 2026, Google released Gemini Embedding 2, which they describe as their first "natively multimodal" embedding model. It takes text, images, video, audio, and documents and projects them all into a single 3072-dimensional embedding space. The model is built on the Gemini foundation, which means modalities interact in the intermediate layers rather than being processed by separate encoders that get stitched together at the end.
The contrast with the text-intermediate approach I described earlier is explicit in Google's framing. They note that most leading models are still "text-first": if you want to search a video library, the AI usually transcribes the video into text first, then embeds that text. Gemini Embedding 2 skips that conversion. It processes audio as waveforms, video as frame sequences, images as patches. The raw signals go through modality-specific encoding, then converge in a shared space where the transformer operates.
The practical difference shows up in latency and fidelity. Because the model sees the original signal rather than a text summary, it preserves information that captions and transcripts lose: tone of voice, spatial relationships, motion patterns, visual details that are hard to describe in words.
There's another detail worth noting. The model uses Matryoshka Representation Learning (MRL), which structures the embedding so the first N dimensions hold the most important information. You can truncate a 3072-dimensional embedding to 768 or 256 dimensions and still get useful results. The first dimensions capture coarse-grained meaning, later dimensions add finer detail. It's efficiency within efficiency: not just the core algorithm unchanged, but the output representation itself designed for flexible compression.
All of this points in the same direction as Karpathy's claim. Gemini Embedding 2 is impressive, but it's impressive because of what it projects into the shared embedding space, not because it changes the core operations once embeddings are there.
Where Does This Break Down?
Diffusion models are the clearest challenge to Karpathy's claim.
Diffusion and autoregressive models solve the same problem (generate data from a learned distribution) but they factorize the joint distribution differently. Autoregressive models generate tokens one at a time, conditioning on all previous tokens. Diffusion models start with noise and iteratively denoise across the entire output simultaneously.
This isn't an efficiency difference. The loss function is different. The generation dynamics are different. The training procedure is different.
You can use transformers inside diffusion models (DiT architectures do exactly this), but the overall paradigm isn't reducible to next-token prediction. Some researchers have drawn connections between diffusion and autoregression, but the framing still feels like a different algorithm, not a more efficient implementation of the same one.
Diffusion language models are an active research area. Google's Gemini Diffusion, LLaDA from GSAI, and others are exploring whether the advantages of diffusion (parallel generation, easier controllability) can transfer to text. The results are promising but not definitive. And the fact that this is an open research question suggests it's not just efficiency.
Reasoning and chain-of-thought is another area where I'm uncertain. Test-time compute (thinking longer to get better answers) doesn't change the core algorithm, but RLHF and reasoning fine-tuning fundamentally change what the model learns to do with that algorithm. A model trained to externalize reasoning steps in token space behaves very differently from a base model doing next-token prediction on documents. You could argue this is "just" a training distribution shift. But training distribution shifts that change behavior this dramatically feel like they're at the boundary of what "efficiency" means.
The Takeaway
Karpathy's claim is useful and mostly right. For MoE, multimodality, tokenization schemes, distributed training, and quantization, the core algorithm really is what microgpt shows. These are engineering achievements that scale and optimize the atomic unit.
Diffusion is the clearest counterexample I can find. Reasoning may be another, depending on how you draw the boundaries.
The architecture is straightforward once you see it: encoders and projectors convert diverse inputs into token embeddings, the transformer processes them, and output decoders convert back when needed. Gemini Embedding 2 is a production-scale demonstration that this works across five modalities.
If you want to understand what LLMs actually do, microgpt is still the best place to start. And for most of what's been built on top of it, "everything else is efficiency" really does hold. Diffusion remains the exception.
Further Reading
The core claim:
- microgpt - Andrej Karpathy's 200-line pure Python GPT implementation. The accompanying blog post walks through every component: tokenizer, autograd engine, transformer architecture, and training loop.
Mixture of Experts:
- Introducing gpt-oss - OpenAI's announcement of their first open-weight models. Both gpt-oss-120b and gpt-oss-20b use MoE architecture with MXFP4 quantization, demonstrating the "decouple total from active parameters" pattern described above.
Multimodal architectures:
Understanding Multimodal LLMs - Sebastian Raschka's detailed breakdown of how vision-language models handle image encoding, projector layers, and training stages. The clearest explanation I've found of the unified embedding approach.
STORM: Token-Efficient Long Video Understanding for Multimodal LLMs - The NVIDIA Research paper introducing a Mamba-based temporal projector for video understanding. Demonstrates how to capture motion and sequence information before passing to the LLM.
An Easy Introduction to Multimodal RAG for Video and Audio - NVIDIA's documentation on text-intermediate pipelines, where all modalities get converted to text before retrieval and generation.
Localizing Step-by-Step: Multimodal Long Video Temporal Grounding with LLM - The Tsinghua paper that uses text-intermediate approaches for video grounding, with discussion of what information is preserved and lost.
Gemini Embedding 2:
Gemini Embedding 2: Our first natively multimodal embedding model - Google's announcement covering the five supported modalities, 3072-dimensional output, and Matryoshka Representation Learning.
Matryoshka Representation Learning - The original paper introducing nested embeddings that can be truncated to different dimensions while preserving semantic quality.
Diffusion language models:
Gemini Diffusion - Google DeepMind's experimental diffusion-based text model. The landing page explains the iterative refinement process and benchmarks against autoregressive models.
Large Language Diffusion Models (LLaDA) - The first 8B parameter diffusion language model trained from scratch. Demonstrates competitive performance with LLaMA3 8B and notably solves the "reversal curse" that affects autoregressive models.