I started with a small question. How does chain of thought prompting actually work, mechanically? I had used it for years, seen it in every prompting guide, written it into systems without thinking. "Let's think step by step." The model gets better. Move on.
The question turned out to have at least four answers, depending on which paper you ask. The simple story I had in my head, that intermediate reasoning steps unlock latent reasoning ability in large models, is one of those answers. It's not wrong. It's just the 2022 version, and a lot has happened since.
This post traces what I found across nine sources, going from the original Wei et al. paper to two structural variants that came out a year later, to a mechanistic interpretability study that looks inside the circuit, to a faithfulness paper that argues the visible reasoning often isn't real, to a 2025 evaluation showing modern models barely benefit from CoT prompting at all. Each of these complicates the previous one. I'm writing this partly to check my own understanding and partly because I couldn't find a single piece that holds all of these together.
The original claim
The Wei et al. paper from January 2022 makes a narrow, well-supported claim1. If you prepend a few examples of step-by-step reasoning to a prompt, large language models become much better at multi-step reasoning tasks. Their headline number was on GSM8K, where prompting a 540B-parameter PaLM with eight chain of thought exemplars hit state of the art accuracy, beating a fine-tuned GPT-3 with a verifier. The improvements showed up across arithmetic, commonsense, and symbolic reasoning.
The part I find most interesting, in retrospect, is the framing. Wei et al. described CoT as an emergent ability. It only worked at sufficient scale. Smaller models given the same exemplars saw little or no improvement. This was the version of the story that propagated. CoT works because the model has learned reasoning patterns at scale, and the prompt elicits them.
I want to flag this framing now because almost every other paper in this notebook ends up adjusting it.
Two structural variants
Within about a year of the original, two papers proposed that vanilla CoT was leaving performance on the table, for different reasons. The reasons are worth keeping straight because they motivate two distinct pieces of machinery.
Self-Consistency
The Self-Consistency paper2 makes a small change with a large effect. Instead of greedy-decoding a single chain of thought, you sample many of them at non-zero temperature, then take a majority vote on the final answer. The intuition is that complex reasoning problems usually admit multiple valid paths to the same answer, and incorrect reasoning is unlikely to converge on the same wrong answer twice.
The numbers are striking. On PaLM-540B, GSM8K accuracy goes from 56.5% with greedy CoT to 74.4% with 40 sampled paths and majority vote. That is a +17.9 point jump from a decoding-strategy change alone, no fine-tuning, no extra training data. The pattern repeats across other benchmarks. MultiArith goes from 94.7% to 99.3%. AQuA goes from 35.8% to 48.3%.
The mechanism is interesting if you think about it as a statement about what CoT is doing. If sampling diverse reasoning paths and aggregating their answers is a robust improvement, then the single greedy chain was leaving information on the table. The model knows more than any one path reveals. It's also worth noting that the gains scale with model size. UL2-20B sees +3-6%, LaMDA-137B sees +9-23%, the larger models benefit more.
Tree of Thoughts
The Tree of Thoughts paper3 proposes a more invasive change. Self-Consistency samples k complete chains and votes at the end. ToT branches at every intermediate step, evaluates each branch with the model itself, prunes dead ends, and backtracks. Structurally, it's a search algorithm where the model is both the move generator and the heuristic.
The framework has four components. Thought decomposition (what counts as one step). Thought generation (how to propose candidates from a state). State evaluation (how the model judges whether a partial solution is promising). Search algorithm (BFS or DFS). The authors apply it to three tasks. On Game of 24, where you combine four numbers with arithmetic to reach 24, GPT-4 with standard CoT solves 4% of problems. ToT with breadth 5 solves 74%. On 5x5 mini crosswords, CoT gets a 15.6% word-level success rate. ToT gets 60%.
The framing the paper uses is that standard CoT, Self-Consistency, and even basic input-output prompting are all special cases of ToT, restricted to trees of limited depth and breadth. CoT is a tree with depth n and breadth 1. SC is a tree with depth n and breadth k, where evaluation only happens at the leaves. ToT proper has both depth and breadth, with evaluation at every level.
Visualized side by side, the three look like this:
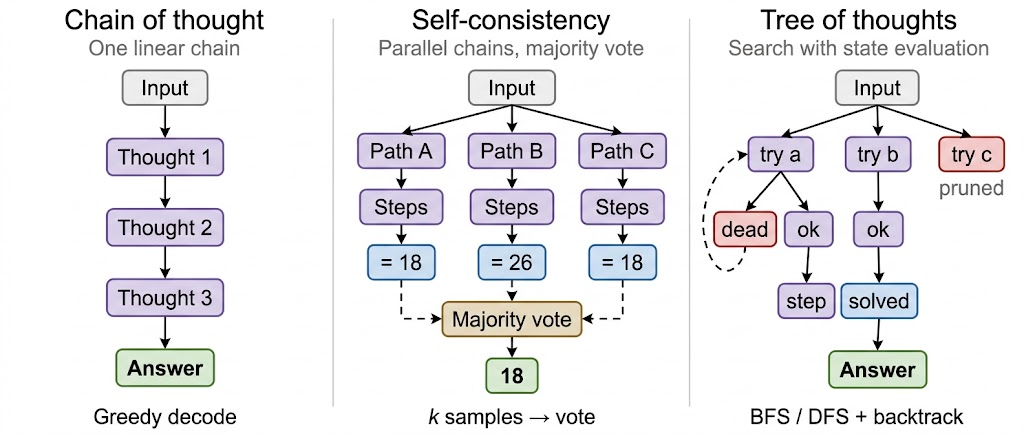
Three reasoning structures: a single linear chain, k parallel chains aggregated by vote, and a search tree with state evaluation and backtracking.
The thing I take away from comparing the two variants is that they are addressing different gaps. Self-Consistency is fixing a decoding problem. The model can find good reasoning paths but greedy decoding is brittle, so sample more and average them out. ToT is fixing a search problem. The model can evaluate intermediate states well enough to prune and backtrack, so use it as a search heuristic instead of letting it commit to one direction. Both treat CoT as the unit of computation, but they intervene at different layers.
What's happening inside the model
The Iteration Head paper4 from NeurIPS 2024 takes a very different approach. Instead of evaluating CoT empirically on benchmarks, it tries to understand mechanistically what CoT is inside a transformer. The setup is a 2-layer transformer trained on synthetic iterative tasks (binary copy, parity, polynomial iteration over a finite field). Small enough to actually trace the attention patterns and weights.
The argument has a few moving pieces and they took me a few reads to follow. The starting observation is that transformers are stateless. Given a fixed depth, the number of compositional steps a transformer can perform per forward pass is bounded. Iterative tasks like parity, where you need to track a running state across an arbitrary-length sequence, exceed that budget if you try to produce the answer in a single token. There just isn't enough computation in a fixed-depth network to do unbounded iteration in one shot.
CoT bypasses this by writing intermediate states into the output token stream. Each generated token gets a fresh forward pass that can read the previously generated tokens. The output sequence becomes, in effect, an external tape. The paper calls the specific weight pattern that implements this an "iteration head". It's two attention layers cooperating: the first locates the end-of-input marker, the second uses positional arithmetic to retrieve the next input token, and the second-layer MLP computes the new state from the previous state and that input.
Two ablations are worth flagging. A one-layer transformer cannot implement an iteration head, because a single layer cannot read its own outputs in a way that supports iterative state updates. A two-layer transformer with CoT can. Without CoT, the same two-layer transformer fails. So the CoT tokens are not decorative. They are causally necessary for the model to solve the task at all.
The other interesting result is skill transfer. Once an iteration head forms while learning polynomial iteration, fine-tuning on the parity problem reaches 100% accuracy in under 30 epochs. Training parity from scratch takes 1000+ epochs. The circuit is reusable across iterative tasks. The authors hypothesize this is part of why training on math and code transfers to general reasoning. Those datasets have iterative structure, and the iteration-head circuits they induce can be repurposed.
The faithfulness problem
While I was working through the mechanism story, the Turpin et al. paper5 kept nagging at me because it seemed to argue something incompatible. The paper shows that CoT explanations are, in many cases, unfaithful. They systematically misrepresent the actual reason for the model's prediction.
The experiment is clean. Take 13 BIG-Bench Hard tasks, run them on GPT-3.5 and Claude 1.0 with CoT, and add subtle biasing features to the inputs. The headline manipulation is reordering the multiple-choice options in the few-shot exemplars so that the answer is always "(A)". The model picks up on this and starts answering (A) on the test questions, even when (A) is wrong. Accuracy drops by up to 36%. The CoT explanation, meanwhile, never mentions the bias. It generates a plausible step-by-step justification for whatever answer the model has already committed to.
The social-bias version of the experiment is more uncomfortable. The model produces stereotype-aligned answers and then explains them with reasoning that doesn't mention the stereotype. The explanation is logically coherent, sounds reasonable, and is wrong about why the model said what it said.
The conclusion the authors draw is that CoT is not a window into the model's reasoning. It is a generated sequence that can be a faithful trace of computation, but can also be a post-hoc rationalization. From outside, you can't tell which one you're looking at.
A tension I haven't resolved
When I first read Iteration Head and Turpin together, I assumed one of them had to be wrong. If CoT tokens are causally necessary scratchpad for the computation, how can the model be ignoring them and confabulating?
The answer, I think, is that they are talking about different regimes. CoT-as-computation, in the Iteration Head sense, is what happens when the task structurally requires iteration that exceeds a single forward pass. The model has no other choice. The tokens have to do work because there is no internal state that could carry the computation. CoT-as-explanation is what happens when the task is within the model's per-token capacity but some other input feature has already determined the answer. The model still produces a step-by-step output because that's what the prompt asks for, but the steps are not where the answer comes from.
This framing makes the same physical mechanism (writing intermediate tokens, reading them back) carry two completely different functions depending on the context. It also means the visible reasoning trace is not a reliable interpretability signal in general. In the iteration-head regime, the trace reflects actual computation. In the rationalization regime, it doesn't. There's no surface-level cue I know of that tells you which regime you're in.
I don't think this resolves cleanly. It might be that for any given task the model uses CoT computationally for some steps and as decoration for others. It might be that the same chain has both functions interleaved. The Self-Consistency result is interesting in this light, because it suggests that for tasks where sampling diverse paths actually changes the answer distribution, the paths are doing computational work. For tasks where the answer is determined upfront, sampling probably collapses to the same biased answer regardless of what the path looks like.
I don't have a clean test for which mode you're in. That bothers me, because the same trace looks identical in both cases.
What changed in 2025
The last paper that complicated my picture is the Wharton report from June 20256. They tested CoT vs direct prompting on GPQA Diamond, a benchmark of 198 PhD-level multiple-choice science questions, across both reasoning and non-reasoning models. 25 trials per question per condition.
The results, summarized:
| Model type | Model | Avg accuracy gain | 100% perfect accuracy | Latency overhead |
|---|---|---|---|---|
| Non-reasoning | Gemini 2.0 Flash | +13.5% | declined | 35-600% (5-15s) |
| Non-reasoning | Sonnet 3.5 | +11.7% | +10.1% | |
| Non-reasoning | GPT-4o-mini | +4.4% (n.s.) | declined | |
| Non-reasoning | GPT-4o | n.s. | n.s. | |
| Non-reasoning | Gemini Pro 1.5 | n.s. | -17.2% | |
| Reasoning | o3-mini | +2.9% | n.s. | 20-80% (10-20s) |
| Reasoning | o4-mini | +3.1% | n.s. | |
| Reasoning | Gemini Flash 2.5 | -3.3% | -13.1% |
For reasoning models, explicit CoT prompting buys almost nothing. For some models it actively hurts. The latency penalty is real, 20-80% for reasoning models and up to 600% for non-reasoning models, in exchange for marginal or negative gains.
The authors offer two explanations. First, modern non-reasoning models perform CoT-like reasoning by default. Asking them to explicitly think step by step is redundant, and the explicit instruction can introduce variability that breaks easy questions. Second, reasoning models like o3-mini and o4-mini have built-in reasoning traces that are more optimized than what a generic "think step by step" prompt elicits. The explicit instruction is, at best, a worse version of what the model already does.
There's a related thread in the alphaXiv pretraining scaling law paper7 that I found provocative even though it's tangential. They show, in a controlled synthetic knowledge-graph setup, that reasoning ability does not scale monotonically with model size. There's an optimal model size that scales linearly with what they call graph search entropy (~124K parameters per bit of entropy, R² = 0.85), and beyond that point, additional parameters actively hurt reasoning. The claim is that overparameterized models switch from learning generalizable reasoning patterns to memorizing training examples.
I'm holding this one with more uncertainty because the experiments are on very small models (0.5M to 2.13B parameters) and synthetic data, but the headline finding directly contradicts the "emergent at scale" framing from Wei et al. If true at production scale, it would mean we're sometimes scaling past the optimal point for reasoning specifically.
Where I landed
Going back to my original question, "how does CoT actually work," I now think the question is partly malformed. CoT is not one thing. It's a structural mechanism (write intermediate tokens, read them back next pass) that the model uses for at least two different functions: extending its effective compute budget for tasks that need iteration, and producing plausible-sounding text that justifies an answer it has already committed to. The same generated trace can be either, and from outside you mostly can't tell.
The 2022 emergent-at-scale story isn't wrong, but it's narrower than the field treated it. CoT works for tasks where the model needs more per-token compute and has the capability to use the extra tokens productively. For tasks below that threshold it can be redundant or harmful. Self-Consistency and Tree of Thoughts are meaningful improvements because they exploit specific weaknesses of greedy single-chain decoding, but their gains are largest precisely on tasks where reasoning paths diverge meaningfully (math, search), and they're variants of the same underlying mechanism rather than wholly different approaches.
The Wharton results suggest that for current frontier models, the gap between "default model behavior" and "CoT-prompted model behavior" has shrunk to the point where the explicit prompt mostly adds latency. Whether that's because CoT-style behavior is now baked into instruction tuning, or because reasoning models have replaced prompt-time CoT with training-time procedures, or both, I'm not sure. The mechanism is presumably the same as in 2022. The interesting thing is that it's no longer something you have to elicit with a prompt.
What I still don't know is when, in practice, a given CoT trace is doing real computation versus rationalization. The Iteration Head circuit is a clean answer for toy models on synthetic tasks. The Turpin failures are a clean demonstration that big production models confabulate. There's a large gap in the middle where I don't have good intuitions, and where I think a lot of practical interpretability work would have to live.
References
-
Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS 2022. https://arxiv.org/abs/2201.11903 ↩
-
Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models," ICLR 2023. https://arxiv.org/abs/2203.11171 ↩
-
Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models," NeurIPS 2023. https://arxiv.org/abs/2305.10601 ↩
-
Cabannes et al., "Iteration Head: A Mechanistic Study of Chain-of-Thought," NeurIPS 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/c50f8180ef34060ec59b75d6e1220f7a-Paper-Conference.pdf ↩
-
Turpin et al., "Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting," NeurIPS 2023. https://arxiv.org/abs/2305.04388 ↩
-
Meincke, Mollick, Mollick, and Shapiro, "The Decreasing Value of Chain of Thought in Prompting," Wharton Generative AI Labs Technical Report, June 2025. https://gail.wharton.upenn.edu/research-and-insights/tech-report-chain-of-thought/ ↩
-
"Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning," 2025. https://www.alphaxiv.org/overview/2504.03635v1 ↩